
Meta is thrilled to introduce the first two models of Meta Llama 3, their latest innovation in the artificial intelligence (AI) landscape. These new models boast 8 billion (8B) and 70 billion (70B) parameters, making them incredibly powerful and versatile. They are pre-trained and instruction-fine-tuned to support a wide array of use cases. From language translation to advanced data analytics, Llama 3 is designed to set new standards in the AI industry.
Why Llama 3?
Meta aimed to build the best open-source AI models that compete with even the top proprietary models available today. Llama 3 responds to developer feedback by being more helpful while also ensuring responsible use. With a commitment to open-source principles, Meta is releasing these models early to enable the community to refine and improve them further. The vision is to make Llama 3 multilingual, multimodal, and capable of handling longer contexts, continually improving on core functionalities like reasoning and coding.
Key Features and Improvements
Unmatched Performance
The 8B and 70B parameter models set new benchmarks for performance. Improvements in pretraining and post-training have made these the best models available today. By refining post-training procedures, Meta has significantly reduced false refusal rates, improved alignment, and increased diversity in model responses. These enhancements have boosted Llama 3’s capabilities in areas like reasoning, code generation, and instruction-following.
Real-World Optimization
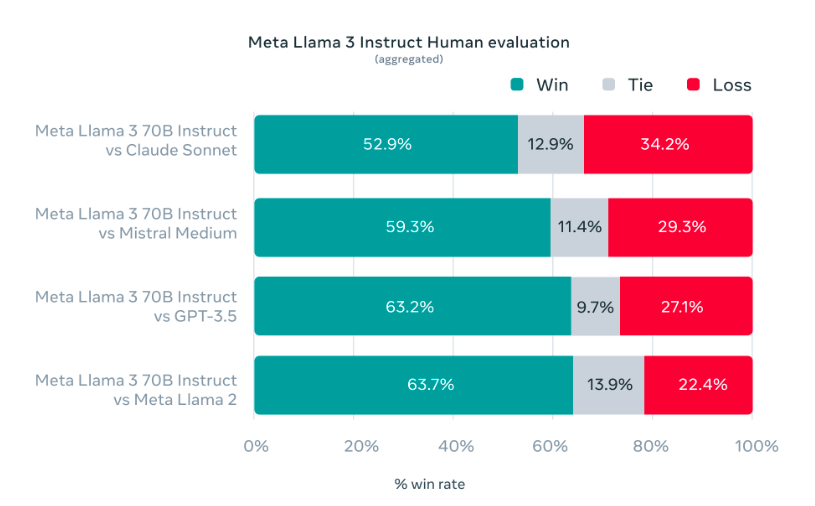
During development, Meta focused on optimizing Llama 3 for real-world scenarios. They created a new, high-quality human evaluation set containing 1,800 prompts across 12 key use cases, such as advice, brainstorming, classification, coding, and summarization. Human evaluations demonstrate that the 70B instruction-following model outperforms competing models of similar size in real-world scenarios.
Simplified Architecture
Llama 3 adopts a standard decoder-only transformer architecture, improved from its predecessor, Llama 2. Utilizing a tokenizer with a 128K token vocabulary, Llama 3 encodes language more efficiently, leading to better performance. The introduction of grouped query attention (GQA) further enhances inference efficiency for both the 8B and 70B parameter sizes.
High-Quality Training Data
Training Llama 3 involved curating an extensive dataset comprising over 15 trillion (15T) tokens from publicly available sources. The dataset is seven times larger than what was used for Llama 2, with a notable increase in coding data. To ensure data quality, Meta implemented advanced filtering pipelines and semantic deduplication techniques.
Scaled Pretraining
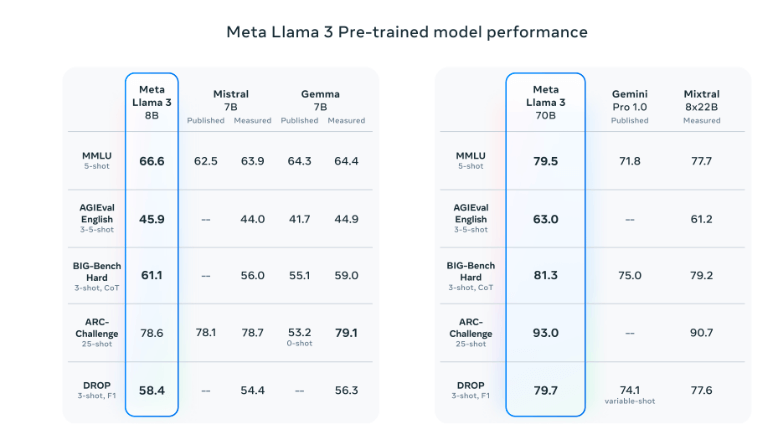
To maximize the benefits of the extensive dataset, Meta scaled up their pretraining efforts. They developed detailed scaling laws to optimize data usage and predict model performance, ensuring that the largest models excel across various tasks. For instance, the models showed consistent improvement even after training on 15T tokens, thanks to efficient training techniques.
Advanced Instruction Fine-Tuning
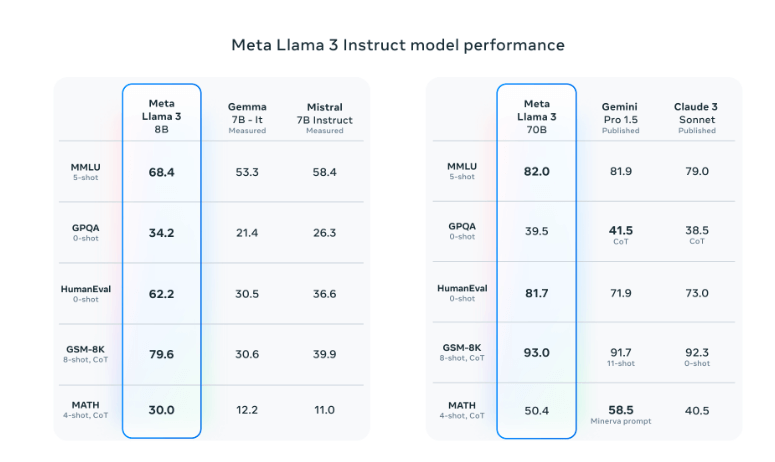
Unlocking the full potential of Llama 3 required innovations in instruction fine-tuning. Meta employed a combination of supervised fine-tuning (SFT), rejection sampling, proximal policy optimization (PPO), and direct preference optimization (DPO). These techniques significantly improved the model’s performance in reasoning and coding tasks.
Building with Llama 3
Meta’s goal is to empower developers to customize Llama 3 for their specific needs. They are providing new trust and safety tools, such as Llama Guard 2 and Cybersec Eval 2, along with Code Shield for filtering insecure code. Meta also co-developed Torchtune, a new PyTorch-native library for fine-tuning and experimenting with LLMs. Torchtune integrates seamlessly with popular platforms like Hugging Face and Weights & Biases.
Promoting Responsible Use
Responsibility is at the core of Llama 3’s development. The models have undergone extensive testing for safety through both internal and external efforts. Meta adopted a system-level approach to responsible deployment, ensuring that developers remain in control while leveraging Llama 3’s capabilities. An updated Responsible Use Guide (RUG) provides comprehensive guidelines for developing and deploying LLMs safely.
Deploying Llama 3
Llama 3 will soon be available on all major platforms, including cloud providers and API providers. Benchmarks show improved token efficiency and inference performance, making Llama 3 not only powerful but also highly efficient. Meta’s open-source code resources, like Llama Recipes, offer everything needed for fine-tuning, deployment, and model evaluation.
What’s Next?
The 8B and 70B models are just the beginning. Meta’s larger models, boasting upwards of 400 billion parameters, are still in training but are already showing promising results. In the coming months, Meta will release models with new capabilities, including multimodality and multilingual support. A detailed research paper will follow, providing deeper insights into their development process.
Join the Journey
Meta believes that openness fosters innovation, better products, and a healthier market. By taking a community-first approach, they are ensuring that Llama 3 benefits everyone. Starting today, these models are available on leading cloud, hosting, and hardware platforms, with more to come.
Conclusion
Meta Llama 3 is set to revolutionize the AI landscape with its cutting-edge features and user-friendly design. By pushing the boundaries of what AI can achieve, Meta is paving the way for a future where intelligent machines play a crucial role in enhancing daily lives. Whether in healthcare, finance, education, or customer service, Llama 3 offers a powerful solution to elevate operations and drive success.

